All papers that have not been peer-reviewed will not appear here, including preprints. You can access my all of papers at 🔗Google Scholar.
2026
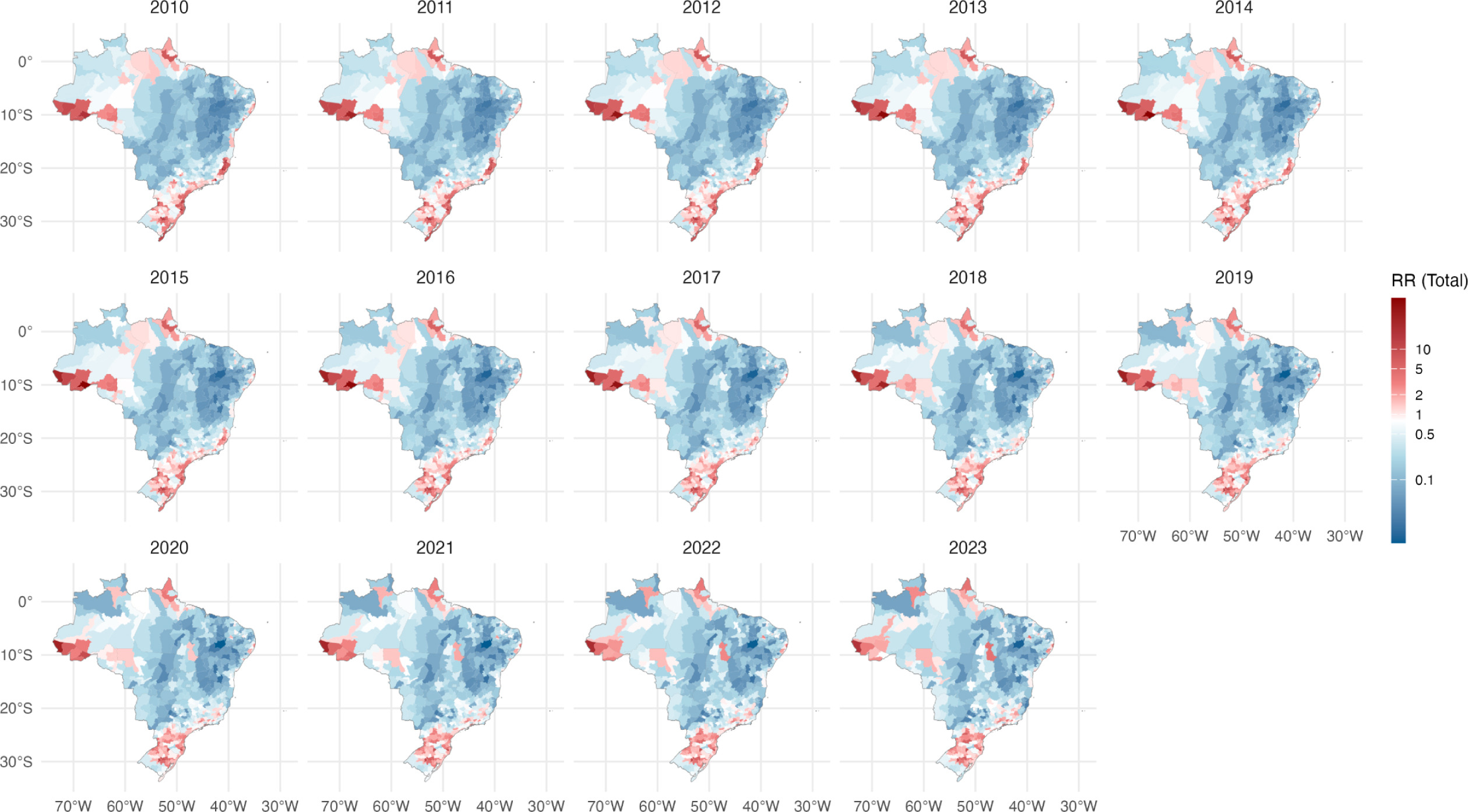
Spatio-temporal dynamics of leptospirosis in Brazil between 2010 and 2023: identifying high-risk regions and gender-specific patterns
Acta Tropica 2026 SCI Q1
Leptospirosis remains a major neglected zoonotic disease in tropical regions, with Brazil bearing a substantial burden. We conducted a national retrospective analysis of confirmed cases from 2010 to 2023 at the microregional level. Spatio-temporal scan statistics identified high-risk clusters, and Bayesian spatio-temporal models estimated annual relative risks (RRs) for total, male, and female populations. A total of 48,190 cases were reported, 80.1% among males. Incidence peaked in 2011 and 2018 and declined during the COVID-19 pandemic. Thirty significant clusters were detected, mainly in Acre and southern Brazil, where persistent elevated risks were observed. Gender-disaggregated analyses revealed heterogeneous patterns across regions. These findings demonstrate marked spatial heterogeneity and gender disparities in leptospirosis risk and underscore the need for targeted, region-specific interventions informed by high-resolution spatio-temporal analysis.
Spatio-temporal dynamics of leptospirosis in Brazil between 2010 and 2023: identifying high-risk regions and gender-specific patterns
Acta Tropica 2026 SCI Q1
Leptospirosis remains a major neglected zoonotic disease in tropical regions, with Brazil bearing a substantial burden. We conducted a national retrospective analysis of confirmed cases from 2010 to 2023 at the microregional level. Spatio-temporal scan statistics identified high-risk clusters, and Bayesian spatio-temporal models estimated annual relative risks (RRs) for total, male, and female populations. A total of 48,190 cases were reported, 80.1% among males. Incidence peaked in 2011 and 2018 and declined during the COVID-19 pandemic. Thirty significant clusters were detected, mainly in Acre and southern Brazil, where persistent elevated risks were observed. Gender-disaggregated analyses revealed heterogeneous patterns across regions. These findings demonstrate marked spatial heterogeneity and gender disparities in leptospirosis risk and underscore the need for targeted, region-specific interventions informed by high-resolution spatio-temporal analysis.
2025
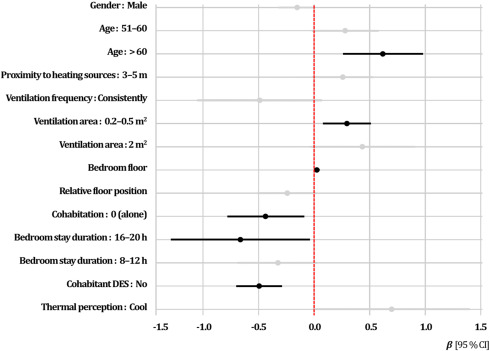
Impact of wintertime indoor hygrothermal conditions and adaptation behavior on dry eye syndrome
Xinyuan Dang *, Xiang Chen *, Haoxiang Chen, Yu Zhao, Guangqi An (* equal contribution)
Journal of Building Engineering 2025 SCI Q1
Dry eye syndrome (DES) is a prevalent ocular condition influenced by environmental and behavioral factors, particularly during winter season. Indoor microclimates, primarily shaped by spatial configurations, heating, ventilation and air conditioning (HVAC) systems as well as occupant adaptation strategies, have a significant impact on ocular surface health. However, the combined impact of these factors remains insufficiently explored. This study combines knowledge synthesis with empirical investigation to examine how indoor hygrothermal conditions and occupant adaptation behavior influence DES symptom severity in urban households. A structured questionnaire survey is conducted among 437 residents in Zhengzhou, in the heating transitional region of China. Chi-square test and multiple regression analysis are employed to examine the associations between environmental exposures, adaptation behavior and self-reported DES. Findings suggest that the use of air conditioners (AC) or electric heaters, low humidity, proximity to heating sources and poor ventilation are linked to more severe symptoms. In contrast, those who frequently ventilate, use humidifiers, or remain in thermally stable rooms report milder discomfort. Residential characteristics — such as floor level, room size and orientation — also appear to affect symptom patterns. Shared living settings, often marked by warm, dry poorly ventilated environments and behavioral interdependence, further complicate individual DES experiences. Overall, the study identifies the sensitivity of DES to modifiable indoor environmental and behavioral factors, highlighting the need for targeted hygrothermal and behavioral interventions and calls for interdisciplinary collaboration to develop evidence-based, occupant-centered solutions for healthier residential environments.
Impact of wintertime indoor hygrothermal conditions and adaptation behavior on dry eye syndrome
Xinyuan Dang *, Xiang Chen *, Haoxiang Chen, Yu Zhao, Guangqi An (* equal contribution)
Journal of Building Engineering 2025 SCI Q1
Dry eye syndrome (DES) is a prevalent ocular condition influenced by environmental and behavioral factors, particularly during winter season. Indoor microclimates, primarily shaped by spatial configurations, heating, ventilation and air conditioning (HVAC) systems as well as occupant adaptation strategies, have a significant impact on ocular surface health. However, the combined impact of these factors remains insufficiently explored. This study combines knowledge synthesis with empirical investigation to examine how indoor hygrothermal conditions and occupant adaptation behavior influence DES symptom severity in urban households. A structured questionnaire survey is conducted among 437 residents in Zhengzhou, in the heating transitional region of China. Chi-square test and multiple regression analysis are employed to examine the associations between environmental exposures, adaptation behavior and self-reported DES. Findings suggest that the use of air conditioners (AC) or electric heaters, low humidity, proximity to heating sources and poor ventilation are linked to more severe symptoms. In contrast, those who frequently ventilate, use humidifiers, or remain in thermally stable rooms report milder discomfort. Residential characteristics — such as floor level, room size and orientation — also appear to affect symptom patterns. Shared living settings, often marked by warm, dry poorly ventilated environments and behavioral interdependence, further complicate individual DES experiences. Overall, the study identifies the sensitivity of DES to modifiable indoor environmental and behavioral factors, highlighting the need for targeted hygrothermal and behavioral interventions and calls for interdisciplinary collaboration to develop evidence-based, occupant-centered solutions for healthier residential environments.
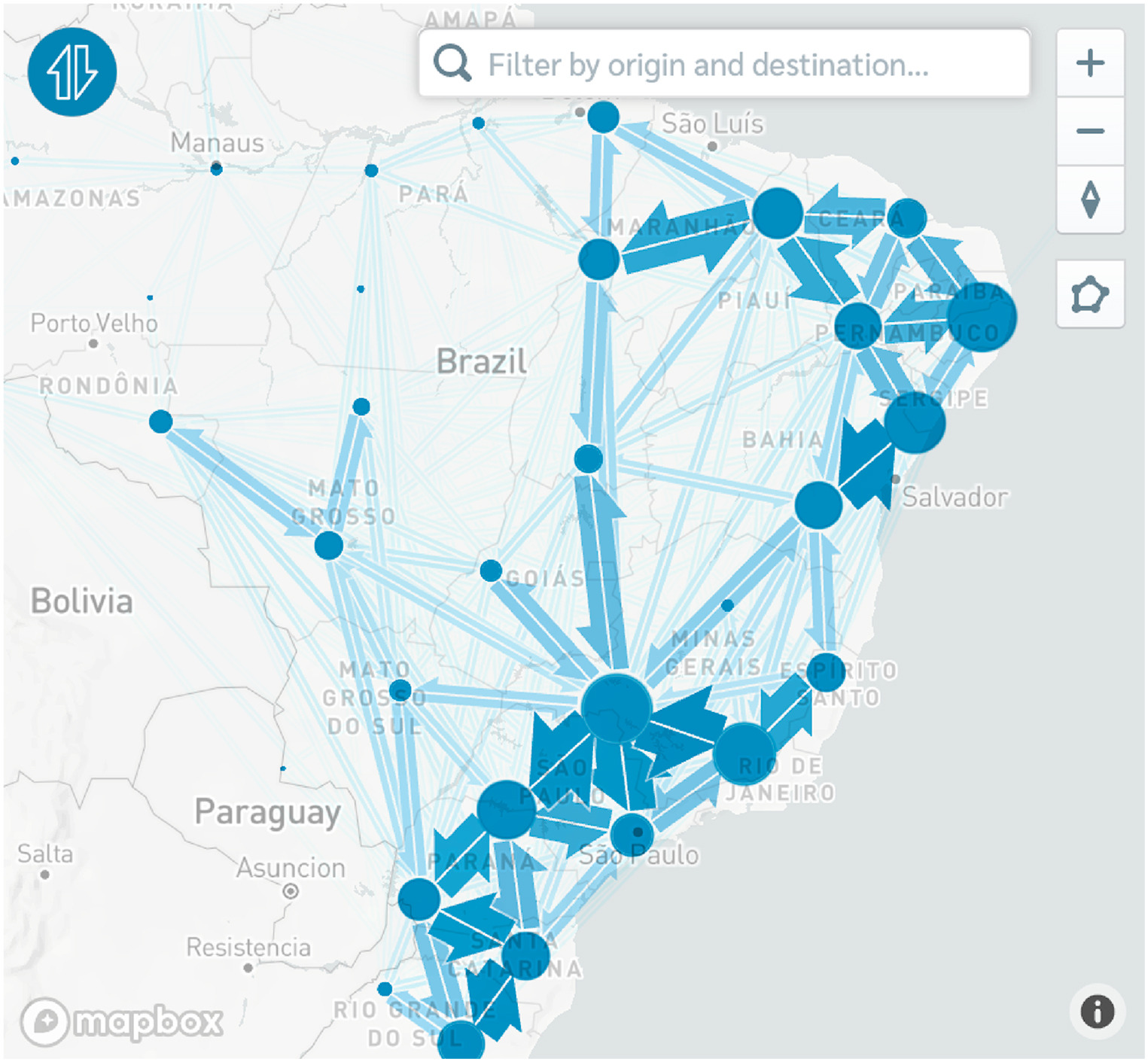
Dengue forecasting and outbreak detection in Brazil using LSTM: integrating human mobility and climate factors
Infectious Disease Modelling 2025 SCI Q1
Dengue fever remains a major public health challenge in Brazil, driven by climate conditions, socio-environmental factors, and human mobility. We developed an LSTM-based framework to forecast weekly dengue cases and detect outbreaks by integrating historical case data, lagged climate variables (temperature and humidity), and mobility-adjusted imported cases. Model performance was compared with three baselines: case-only LSTM, climate-enhanced LSTM, and climate plus geographic neighborhood LSTM. Forecasting accuracy was evaluated using MAE, MAPE, and CRPS, and outbreak detection was assessed using accuracy, sensitivity, specificity, and F1 score. The mobility-enhanced model consistently outperformed all baselines, achieving lower prediction errors, better-calibrated uncertainty, and higher sensitivity and F1 scores for outbreak detection. These findings demonstrate that incorporating human mobility substantially improves dengue forecasting and early warning performance. The proposed framework is scalable and adaptable, offering practical value for public health planning and potentially extending to other climate- and mobility-sensitive vector-borne diseases.
Dengue forecasting and outbreak detection in Brazil using LSTM: integrating human mobility and climate factors
Infectious Disease Modelling 2025 SCI Q1
Dengue fever remains a major public health challenge in Brazil, driven by climate conditions, socio-environmental factors, and human mobility. We developed an LSTM-based framework to forecast weekly dengue cases and detect outbreaks by integrating historical case data, lagged climate variables (temperature and humidity), and mobility-adjusted imported cases. Model performance was compared with three baselines: case-only LSTM, climate-enhanced LSTM, and climate plus geographic neighborhood LSTM. Forecasting accuracy was evaluated using MAE, MAPE, and CRPS, and outbreak detection was assessed using accuracy, sensitivity, specificity, and F1 score. The mobility-enhanced model consistently outperformed all baselines, achieving lower prediction errors, better-calibrated uncertainty, and higher sensitivity and F1 scores for outbreak detection. These findings demonstrate that incorporating human mobility substantially improves dengue forecasting and early warning performance. The proposed framework is scalable and adaptable, offering practical value for public health planning and potentially extending to other climate- and mobility-sensitive vector-borne diseases.
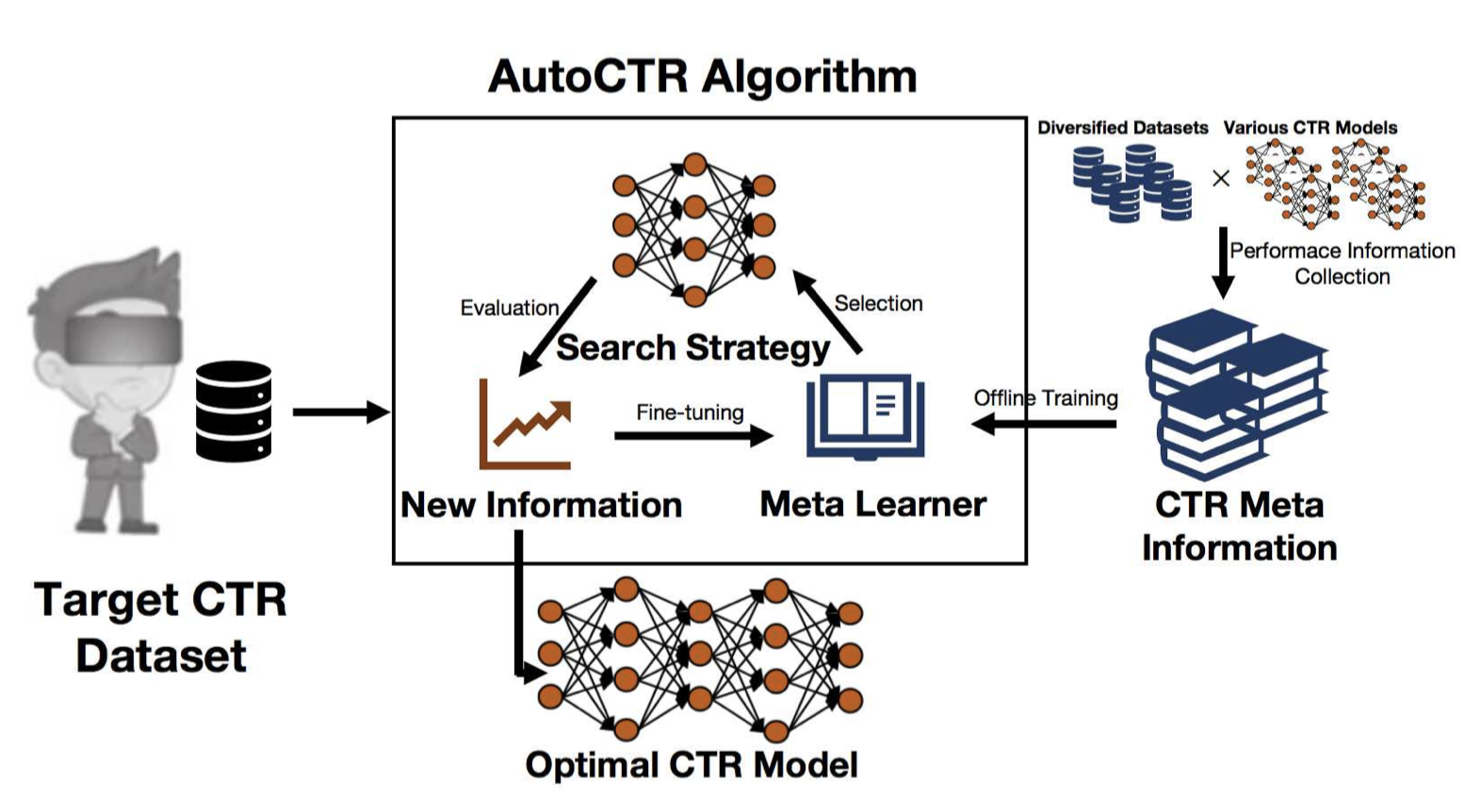
Meta-learning Based CTR Algorithm Selection and Hyperparameter Optimization
Chunnan Wang, Junzhe Wang, Xiang Chen, Xintong Song, Tianyu Mu, Hongzhi Wang
IEEE 41st International Conference on Data Engineering (ICDE) 2025 CCF-A
The existing Click-Through Rate (CTR) algorithms have their own advantages and are sensitive to hyperparameters. Quickly obtaining a high-performance CTR model for a new task can bring good application effects. However, ordinary users fail to do so due to the lack of domain knowledge. In this paper, we remedy this deficiency by proposing AutoCTR, an efficient meta-learning based Combined Algorithm Selection and Hyperparameter Optimization (CASH) algorithm, to help non-expert users quickly find the best CTR model. In AutoCTR, we introduce the meta-learning technique to make full use of the meta-information w.r.t. CTR to guide for the new CTR task. Specifically, we utilize the meta-information to learn characteristics and representations of CTR algorithms with different settings. We use these meta experiences combined with few evaluation information on the target CTR dataset to efficiently exploring the huge CTR CASH search space for the new task. The CTR model representation method has significant influence on the quality of the learned meta experiences. To further enhance the quality, we also design a Graph Neural Network (GNN) based embedding learning method. This method can link different CTR models through their components, and thus quickly learning higher-quality model representations. Extensive experimental results show that AutoCTR can quickly select suitable CTR models for different CTR tasks. Compared with the existing CASH algorithms, which ignore meta-information or rely on a huge amount of meta-information, AutoCTR is more reasonable and efficient.
Meta-learning Based CTR Algorithm Selection and Hyperparameter Optimization
Chunnan Wang, Junzhe Wang, Xiang Chen, Xintong Song, Tianyu Mu, Hongzhi Wang
IEEE 41st International Conference on Data Engineering (ICDE) 2025 CCF-A
The existing Click-Through Rate (CTR) algorithms have their own advantages and are sensitive to hyperparameters. Quickly obtaining a high-performance CTR model for a new task can bring good application effects. However, ordinary users fail to do so due to the lack of domain knowledge. In this paper, we remedy this deficiency by proposing AutoCTR, an efficient meta-learning based Combined Algorithm Selection and Hyperparameter Optimization (CASH) algorithm, to help non-expert users quickly find the best CTR model. In AutoCTR, we introduce the meta-learning technique to make full use of the meta-information w.r.t. CTR to guide for the new CTR task. Specifically, we utilize the meta-information to learn characteristics and representations of CTR algorithms with different settings. We use these meta experiences combined with few evaluation information on the target CTR dataset to efficiently exploring the huge CTR CASH search space for the new task. The CTR model representation method has significant influence on the quality of the learned meta experiences. To further enhance the quality, we also design a Graph Neural Network (GNN) based embedding learning method. This method can link different CTR models through their components, and thus quickly learning higher-quality model representations. Extensive experimental results show that AutoCTR can quickly select suitable CTR models for different CTR tasks. Compared with the existing CASH algorithms, which ignore meta-information or rely on a huge amount of meta-information, AutoCTR is more reasonable and efficient.
Assessing dengue forecasting methods: A comparative study of statistical models and machine learning techniques in Rio de Janeiro, Brazil
Tropical Medicine and Health 2025 SCI Q1
This study demonstrates the strengths and limitations of various methods for dengue forecasting across multiple timeframes. It highlights the best-performing statistical and machine learning methods, including their computational efficiency, underscoring the significance of machine learning techniques and the integration of climate covariates to improve forecasts. These findings offer valuable insights for public health officials, facilitating the development of dengue surveillance systems for more accurate forecasting and timely allocation of resources to mitigate dengue outbreaks.
Assessing dengue forecasting methods: A comparative study of statistical models and machine learning techniques in Rio de Janeiro, Brazil
Tropical Medicine and Health 2025 SCI Q1
This study demonstrates the strengths and limitations of various methods for dengue forecasting across multiple timeframes. It highlights the best-performing statistical and machine learning methods, including their computational efficiency, underscoring the significance of machine learning techniques and the integration of climate covariates to improve forecasts. These findings offer valuable insights for public health officials, facilitating the development of dengue surveillance systems for more accurate forecasting and timely allocation of resources to mitigate dengue outbreaks.
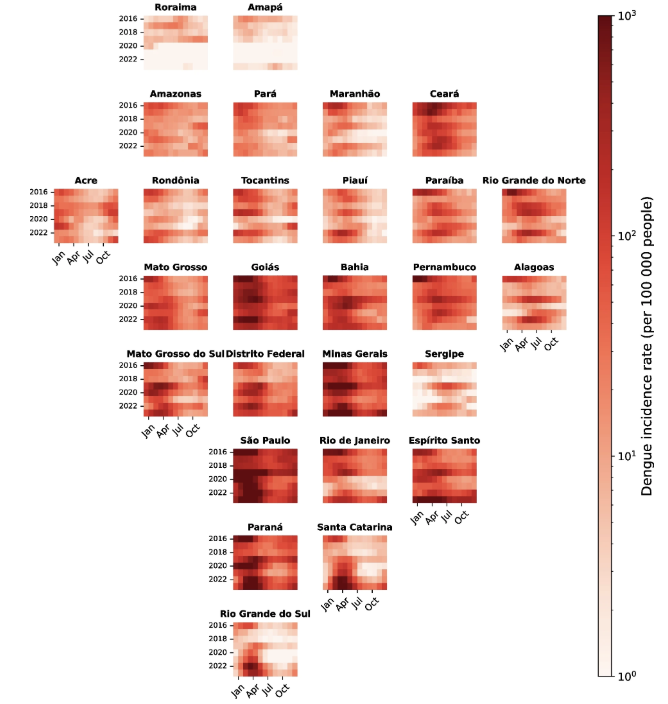
Forecasting dengue across Brazil with LSTM neural networks and SHAP-driven lagged climate and spatial effects
BMC Public Health 2025 SCI Q1
This study presents a scalable and robust framework for dengue forecasting across Brazil, effectively integrating temporal, climatic, and spatial information into an LSTM-based model. The model’s successful application across Brazil’s diverse regions demonstrates its generalizability to other dengue-endemic areas with varying climatic and epidemiological conditions. By integrating diverse data sources, the framework captures key transmission drivers, demonstrating the potential of LSTM neural networks for robust predictions. These findings provide valuable insights to enhance public health strategies and outbreak preparedness in Brazil.
Forecasting dengue across Brazil with LSTM neural networks and SHAP-driven lagged climate and spatial effects
BMC Public Health 2025 SCI Q1
This study presents a scalable and robust framework for dengue forecasting across Brazil, effectively integrating temporal, climatic, and spatial information into an LSTM-based model. The model’s successful application across Brazil’s diverse regions demonstrates its generalizability to other dengue-endemic areas with varying climatic and epidemiological conditions. By integrating diverse data sources, the framework captures key transmission drivers, demonstrating the potential of LSTM neural networks for robust predictions. These findings provide valuable insights to enhance public health strategies and outbreak preparedness in Brazil.
2023
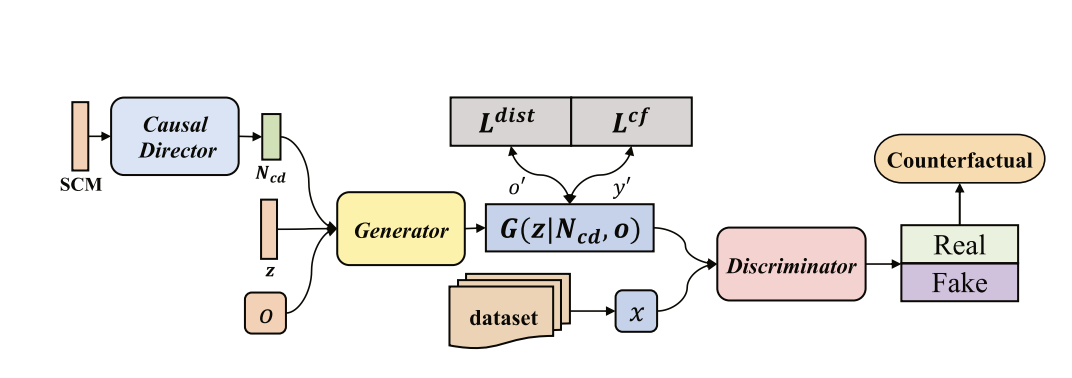
CUBE: Causal Intervention-Based Counterfactual Explanation for Prediction Models
Xinyue Shao, Hongzhi Wang, Xiang Chen, Xiao Zhu, Yan Zhang
IEEE Transactions on Knowledge and Data Engineering (TKDE) 2023 SCI Q1
Recent several years have witnessed the rapid explosion of artificial intelligence applied in various domains with the surpassing human-level performance. Despite the success, these models’ underlying mechanisms remain a mystery, as their complicated representations make human understanding impossible. This mystery may cause discrimination and non-robustness in prediction. Making deep learning models more transparent and understandable is gaining popularity, but most of interpretation approaches provide spurious correlations leading to suboptimal, incorrect or even biased interpretations, which could be reduced by causal explanations. Motivated by this, we attempt to study the generation of causal explanations and propose CUBE, a causal intervention-based counterfactual interpretation method. To ensure that the generation process of counterfactual explanation conforms to causality, we model the counterfactual generation process as a causal graph and construct a counterfactual generation model based on the causal intervention; to generate counterfactuals that adhere to the causality, we introduce a causal director to capture the causal relationships in the distribution and guide the generation of counterfactuals; to improve the efficiency of the counterfactual generation when facing a large number of explanation queries, we model it as a sample generation problem and propose an explainable framework based on adversarial generation. The experimental results validate that CUBE outperforms other approaches in terms of both lower time costs and higher explanation quality.
CUBE: Causal Intervention-Based Counterfactual Explanation for Prediction Models
Xinyue Shao, Hongzhi Wang, Xiang Chen, Xiao Zhu, Yan Zhang
IEEE Transactions on Knowledge and Data Engineering (TKDE) 2023 SCI Q1
Recent several years have witnessed the rapid explosion of artificial intelligence applied in various domains with the surpassing human-level performance. Despite the success, these models’ underlying mechanisms remain a mystery, as their complicated representations make human understanding impossible. This mystery may cause discrimination and non-robustness in prediction. Making deep learning models more transparent and understandable is gaining popularity, but most of interpretation approaches provide spurious correlations leading to suboptimal, incorrect or even biased interpretations, which could be reduced by causal explanations. Motivated by this, we attempt to study the generation of causal explanations and propose CUBE, a causal intervention-based counterfactual interpretation method. To ensure that the generation process of counterfactual explanation conforms to causality, we model the counterfactual generation process as a causal graph and construct a counterfactual generation model based on the causal intervention; to generate counterfactuals that adhere to the causality, we introduce a causal director to capture the causal relationships in the distribution and guide the generation of counterfactuals; to improve the efficiency of the counterfactual generation when facing a large number of explanation queries, we model it as a sample generation problem and propose an explainable framework based on adversarial generation. The experimental results validate that CUBE outperforms other approaches in terms of both lower time costs and higher explanation quality.
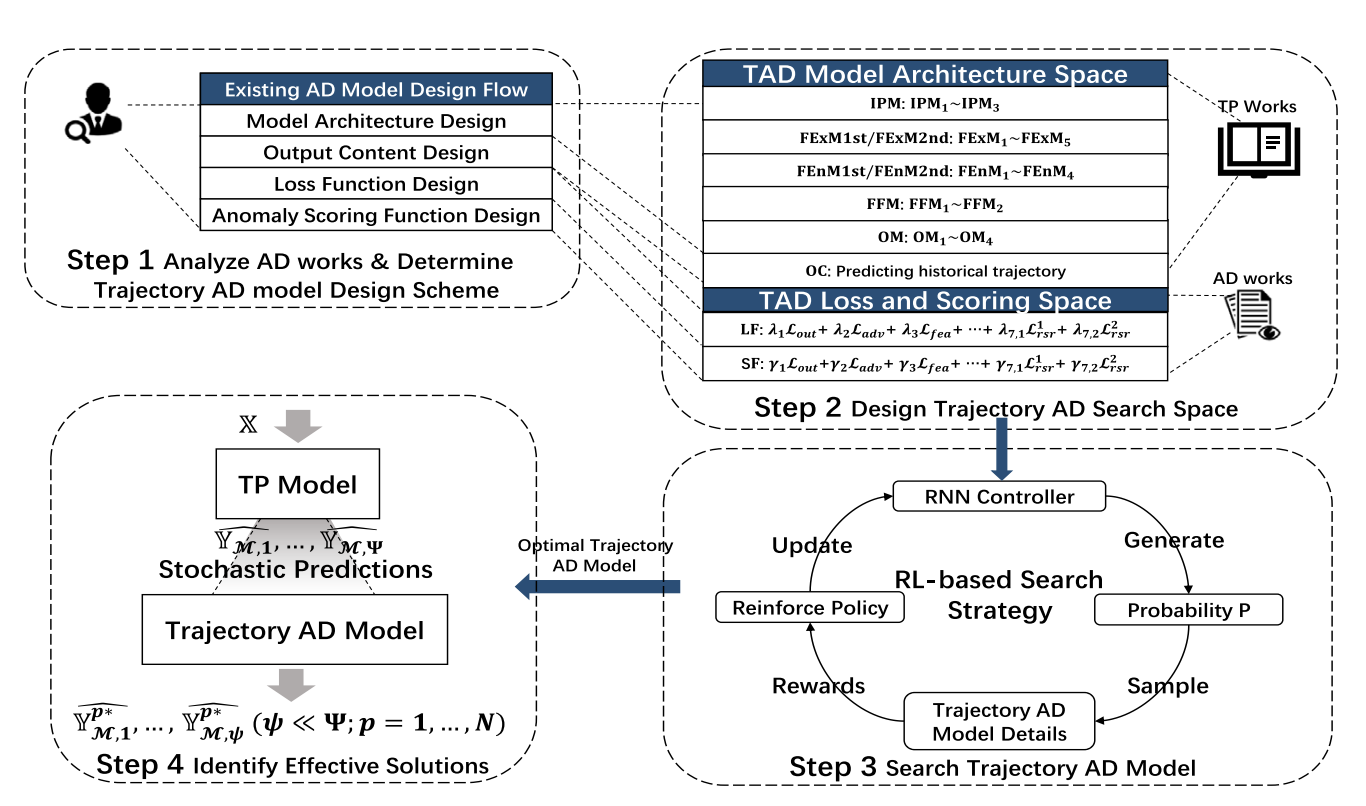
Identifying effective trajectory predictions under the guidance of trajectory anomaly detection model
Chunnan Wang, Liang Chen, Xiang Chen, Hongzhi Wang
Pattern Recognition 2023 SCI Q1
Trajectory Prediction (TP) is an important research topic in computer vision and robotics fields. Recently, many stochastic TP models have been proposed to deal with this problem and have achieved better performance than the traditional models with deterministic trajectory outputs. However, these stochastic models can generate a number of future trajectories with different qualities. They are lack of self-evaluation ability, that is, to examine the rationality of their prediction results, thus failing to guide users to identify high-quality ones from their candidate results. This hinders them from playing their best in real applications. In this paper, we make up for this defect and propose TPAD, a novel TP evaluation method based on the trajectory Anomaly Detection (AD) technique. In TPAD, we firstly combine the Automated Machine Learning (AutoML) technique and the experience in the AD and TP field to automatically...
Identifying effective trajectory predictions under the guidance of trajectory anomaly detection model
Chunnan Wang, Liang Chen, Xiang Chen, Hongzhi Wang
Pattern Recognition 2023 SCI Q1
Trajectory Prediction (TP) is an important research topic in computer vision and robotics fields. Recently, many stochastic TP models have been proposed to deal with this problem and have achieved better performance than the traditional models with deterministic trajectory outputs. However, these stochastic models can generate a number of future trajectories with different qualities. They are lack of self-evaluation ability, that is, to examine the rationality of their prediction results, thus failing to guide users to identify high-quality ones from their candidate results. This hinders them from playing their best in real applications. In this paper, we make up for this defect and propose TPAD, a novel TP evaluation method based on the trajectory Anomaly Detection (AD) technique. In TPAD, we firstly combine the Automated Machine Learning (AutoML) technique and the experience in the AD and TP field to automatically...
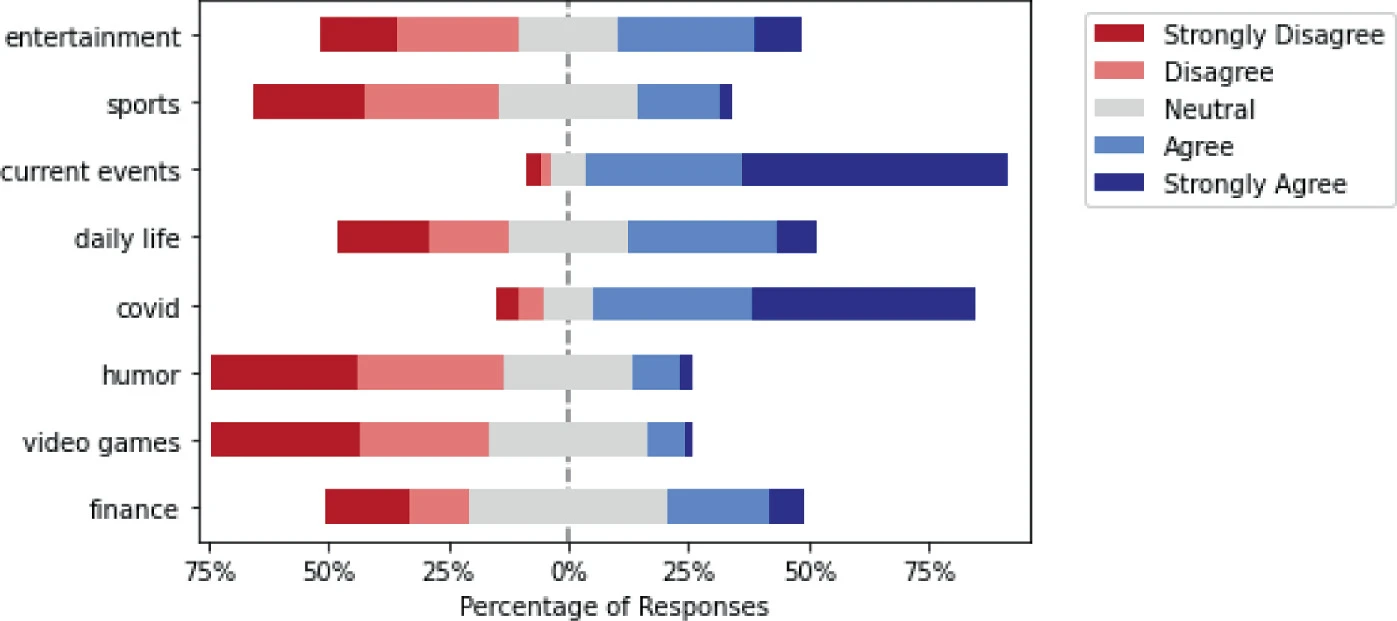
How We Express Ourselves Freely: Censorship, Self-censorship, and Anti-censorship on a Chinese Social Media
Xiang Chen, Jiamu Xie, Zixin Wang, Bohui Shen, Zhixuan Zhou
iConference 2023
Censorship, anti-censorship, and self-censorship in an authoritarian regime have been extensively studies, yet the relationship between these intertwined factors is not well understood. In this paper, we report results of a large-scale survey study with Sina Weibo users toward bridging this research gap. Through descriptive statistics, correlation analysis, and regression analysis, we uncover how users are being censored, how and why they conduct self-censorship on different topics and in different scenarios (i.e., post, repost, and comment), and their various anti-censorship strategies. We further identify the metrics of censorship and self-censorship, find the influence factors, and construct a mediation model to measure their relationship. Based on these findings, we discuss implications for democratic social media design and future censorship research.
How We Express Ourselves Freely: Censorship, Self-censorship, and Anti-censorship on a Chinese Social Media
Xiang Chen, Jiamu Xie, Zixin Wang, Bohui Shen, Zhixuan Zhou
iConference 2023
Censorship, anti-censorship, and self-censorship in an authoritarian regime have been extensively studies, yet the relationship between these intertwined factors is not well understood. In this paper, we report results of a large-scale survey study with Sina Weibo users toward bridging this research gap. Through descriptive statistics, correlation analysis, and regression analysis, we uncover how users are being censored, how and why they conduct self-censorship on different topics and in different scenarios (i.e., post, repost, and comment), and their various anti-censorship strategies. We further identify the metrics of censorship and self-censorship, find the influence factors, and construct a mediation model to measure their relationship. Based on these findings, we discuss implications for democratic social media design and future censorship research.
2022
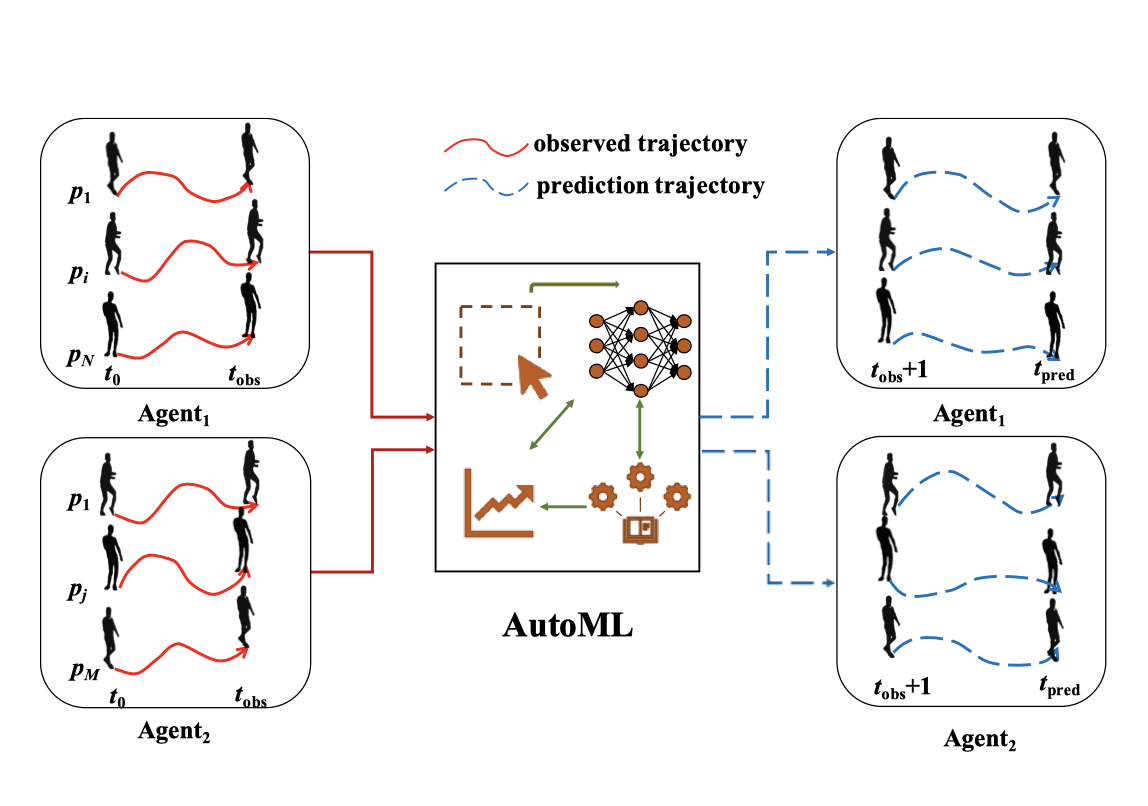
ATPFL: Automatic Trajectory Prediction Model Design Under Federated Learning Framework
Chunnan Wang, Xiang Chen, Junzhe Wang, Hongzhi Wang
Conference on Computer Vision and Pattern Recognition (CVPR 2022) 2022 CCF-A
Although the Trajectory Prediction (TP) model has achieved great success in computer vision and robotics fields, its architecture and training scheme design rely on heavy manual work and domain knowledge, which is not friendly to common users. Besides, the existing works ignore Federated Learning (FL) scenarios, failing to make full use of distributed multi-source datasets with rich actual scenes to learn more a powerful TP model. In this paper, we make up for the above defects and propose ATPFL to help users federate multi-source trajectory datasets to automatically design and train a powerful TP model. In ATPFL, we build an effective TP search space by analyzing and summarizing the existing works. Then, based on the characters of this search space, we design a relation-sequence-aware search strategy, realizing the automatic design of the TP model. Finally, we find appropriate federated training methods to respectively support the TP model search and final model training under the FL framework, ensuring both the search efficiency and the final model performance. Extensive experimental results show that ATPFL can help users gain well-performed TP models, achieving better results than the existing TP models trained on the single-source dataset.
ATPFL: Automatic Trajectory Prediction Model Design Under Federated Learning Framework
Chunnan Wang, Xiang Chen, Junzhe Wang, Hongzhi Wang
Conference on Computer Vision and Pattern Recognition (CVPR 2022) 2022 CCF-A
Although the Trajectory Prediction (TP) model has achieved great success in computer vision and robotics fields, its architecture and training scheme design rely on heavy manual work and domain knowledge, which is not friendly to common users. Besides, the existing works ignore Federated Learning (FL) scenarios, failing to make full use of distributed multi-source datasets with rich actual scenes to learn more a powerful TP model. In this paper, we make up for the above defects and propose ATPFL to help users federate multi-source trajectory datasets to automatically design and train a powerful TP model. In ATPFL, we build an effective TP search space by analyzing and summarizing the existing works. Then, based on the characters of this search space, we design a relation-sequence-aware search strategy, realizing the automatic design of the TP model. Finally, we find appropriate federated training methods to respectively support the TP model search and final model training under the FL framework, ensuring both the search efficiency and the final model performance. Extensive experimental results show that ATPFL can help users gain well-performed TP models, achieving better results than the existing TP models trained on the single-source dataset.
2020

Research on Shrinking City Identification Based on Unsupervised Learning Method--A Case Study of 9 Prefecture-Level Cities in Guangdong-Hong Kong-Macao Greater Bay Area
Zixuan Han, Kangjun Peng, Jianing Mi, Xiang Chen
Journal of Public Administration(公共行政评论) 2020 CSSCI
Urban shrinkage has become a global, local, complex, and multidimensional phenomenon, gaining increasing attention. This study examines nine prefecture-level cities in the Guangdong-Hong Kong-Macao Greater Bay Area (GBA) across economic, population, spatial, and administrative dimensions. Using 2008–2017 panel data and DMSP/OLS nighttime light data, a framework of 44 indicators is established to identify shrinking cities.Through K-means clustering and factor analysis, the study categorizes cities into four types: "population-loss shrinking cities" (Zhaoqing, Jiangmen, Huizhou), "comprehensive expansion cities" (Shenzhen), "spatially stable expansion cities" (Guangzhou), and "stable cities" (Zhuhai, Zhongshan, Dongguan, Foshan). Urban shrinkage in this region is driven by natural constraints, weak policy support, inadequate infrastructure, and demographic shifts.
Research on Shrinking City Identification Based on Unsupervised Learning Method--A Case Study of 9 Prefecture-Level Cities in Guangdong-Hong Kong-Macao Greater Bay Area
Zixuan Han, Kangjun Peng, Jianing Mi, Xiang Chen
Journal of Public Administration(公共行政评论) 2020 CSSCI
Urban shrinkage has become a global, local, complex, and multidimensional phenomenon, gaining increasing attention. This study examines nine prefecture-level cities in the Guangdong-Hong Kong-Macao Greater Bay Area (GBA) across economic, population, spatial, and administrative dimensions. Using 2008–2017 panel data and DMSP/OLS nighttime light data, a framework of 44 indicators is established to identify shrinking cities.Through K-means clustering and factor analysis, the study categorizes cities into four types: "population-loss shrinking cities" (Zhaoqing, Jiangmen, Huizhou), "comprehensive expansion cities" (Shenzhen), "spatially stable expansion cities" (Guangzhou), and "stable cities" (Zhuhai, Zhongshan, Dongguan, Foshan). Urban shrinkage in this region is driven by natural constraints, weak policy support, inadequate infrastructure, and demographic shifts.